VESSL Run
Run any models in seconds
VESSL Run brings a unified interface for training, fine-tuning, and deploying Llama 2,
Stable Diffusion, and more on any cloud, with a single command.

The latest open-source models
that just works
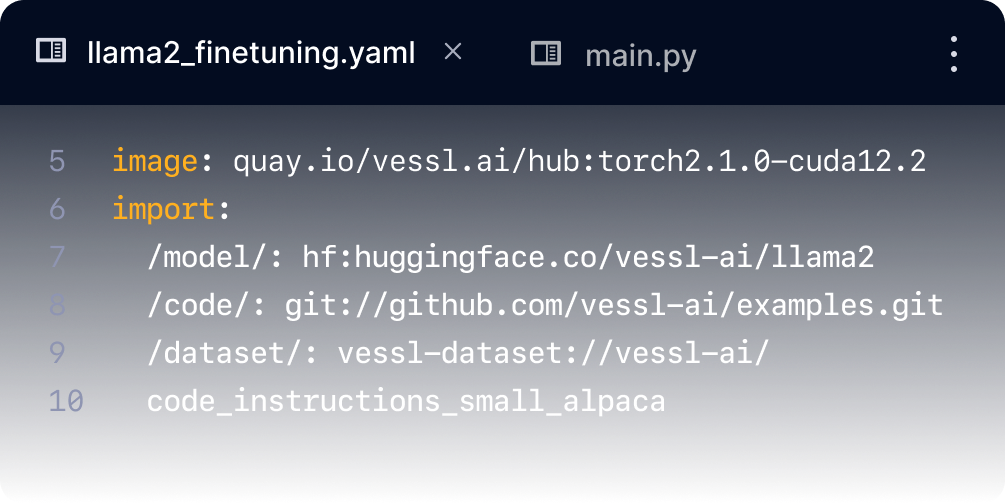
VESSL Run simplifies the manual Python dependency and CUDA configuration into a single YAML definition
so you can spend more time iterating the models. Start training by pointing to GitHub repositories,
our custom Docker images, and your datasets.
1
2
3
4
5
6
7
8
9
10
11
12
- llama2
- fine-tuning
resources:
cluster: vessl-gcp-oregon
accelerators: v1.l4-1.men-27

Launch projects from Git repos
Use public, open-source models as a starting point for your projects simply by pointing to a GitHub repository.

Bring your own datasets
Mount your datasets from the cloud or on-prem storage and fine-tune your model with the same YAML definition.

Custom Docker Images
Our pre-built Docker images remove the need to manually install and configure environment dependencies.
Ready for scale
Fine-tune and deploy models at scale on any cloud without worrying
about the complex compute backends and system details.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
name: llama2_c_inference
description: Batch inference with llama2.c.
tags:
- llama2_c
- inference
image: quay.io/vessl.ai/hub:torch2.1.0-cuda12.2
import:
/model/: hf://huggingface.co/vessl-ai/llama2
/code/: git://github.com/vessl-ai/examples.gi
run:
- command: |-pip install streamlit
wget https://huggingface.co/karpathy/
tinyllamas/resolve/main/stories42M.bin/
streamlit run llama2_c/streamlit//
llama2_c_inference.py --server.port=80/
workdir: /code/
interactive:
max_runtime: 24h
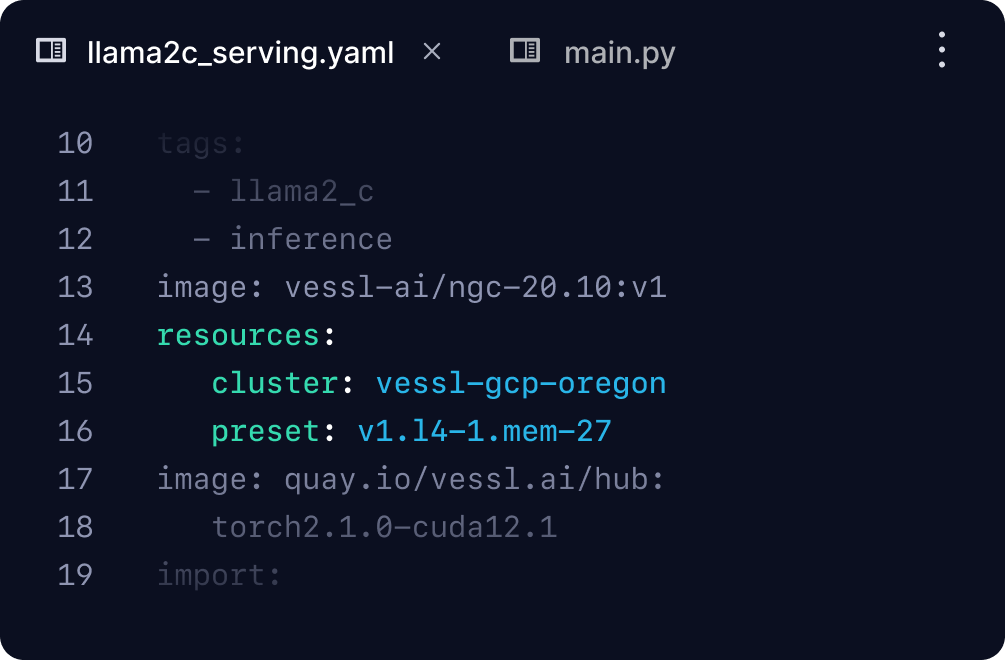
Train on multiple clouds
Launch your Run on any cloud with managed spot instances, elastic scaling, and resource monitoring.




Or bring your own GPUs
Set up unlimited number of Kubernetes-backed on-prem GPU clusters with a single command.
Automatic scaling
- GPU Optimization
- Batch scheduling
- Distributed training
- Termination protection
- Pay by the second
Go beyond training
Add snippets to the existing YAML definition and deploy your model as a micro app or an API with just a single command.
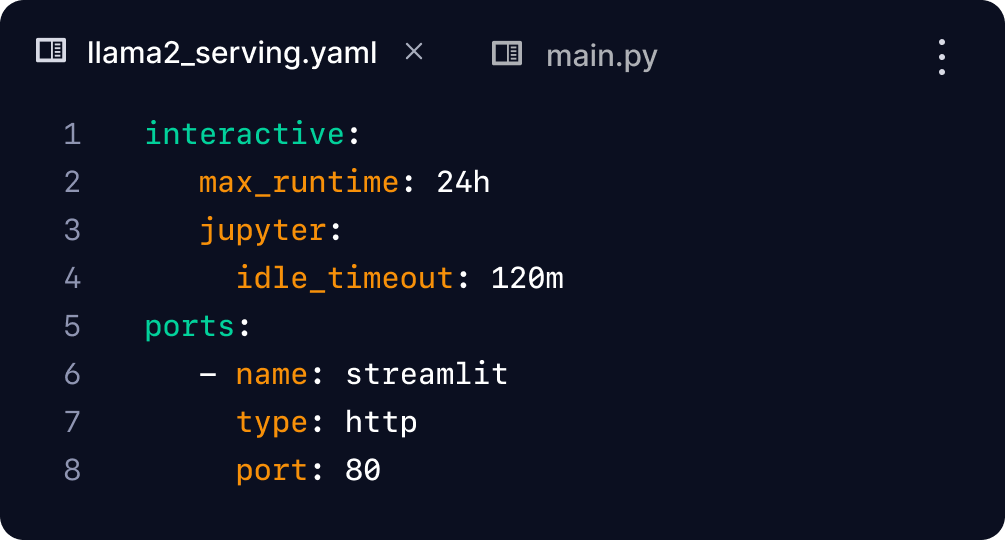
Create your own micro AI app
Open up a port to your Run and integrate tools like Streamlit and Gradio to create interactive apps.
Deploy at scale
Create inference endpoints instantly with multiple ports and get ready for peak usage with autoscaling.
Get started in
under a minute
Launch the latest models like Stable Diffusion and Mistral 7B instantly at our model hub.
Explore models